
Distributed Systems: Key Concepts

Modern software systems rarely operate in isolation. Whether you’re scaling a web app, handling massive datasets, or ensuring uptime, distributed systems play a critical role. But how can engineers design systems that are reliable, fast, and fault-tolerant?
This guide breaks down the essential concepts of distributed systems — stripped of heavy theory — and connects them to practical, real-world scenarios.
What Are Distributed Systems (and Why Do Engineers Need Them)?
A distributed system is a set of computers working together as one unit. This setup helps engineers:
Scale horizontally (e.g., adding more machines to handle traffic).
Handle failures gracefully (e.g., replicating data across multiple nodes).
Ensure high performance (e.g., optimizing for low-latency access).
A typical e-commerce platform relies on:
Compute instances behind a load balancer.
A relational database for transactional data.
Durable file storage replicated across regions.
Fault Tolerance: Preparing for Failures
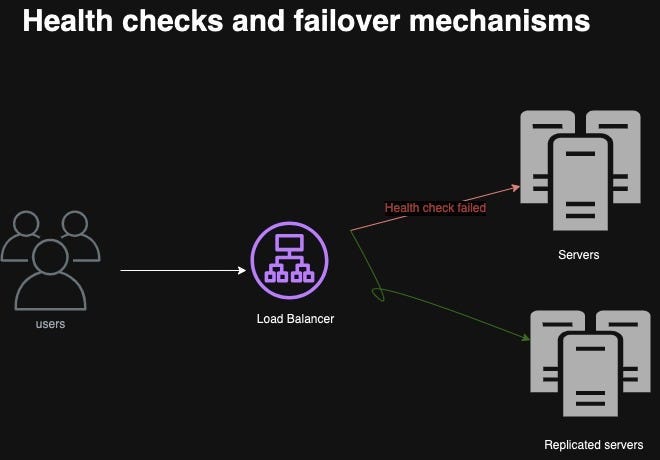
In distributed systems, failures (server crashes, network partitions, etc.) are inevitable. Systems must continue running without disruption.
Strategies for Fault Tolerance:
Data Replication: Store copies of data across multiple nodes to ensure durability.
Health Checks and Failover: Replace unhealthy nodes and reroute traffic to healthy ones.
Monitoring and Recovery: Detect errors and trigger automatic recovery actions.
Real-World Example: During a data center outage, services can maintain access by replicating data across multiple locations. For instance, a streaming service might rely on alarms to trigger scaling or failover processes, keeping the stream uninterrupted.
2. Balancing Consistency and Availability (CAP Theorem)
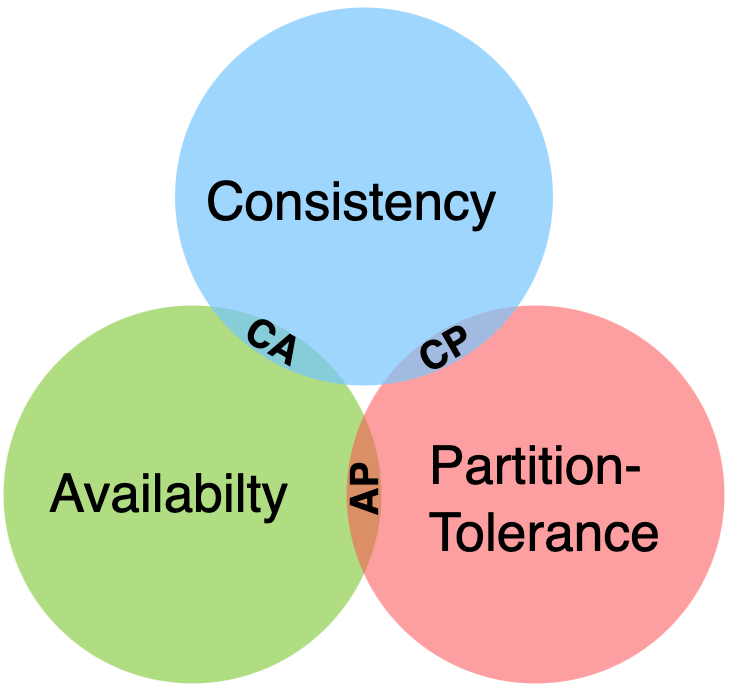
The CAP theorem states that distributed systems can only optimize for two out of three properties:
Consistency: All nodes return the latest data.
Availability: Every request receives a response, even during failures.
Partition Tolerance: The system continues operating despite network failures.
Because network partitions are unavoidable, you must choose between consistency and availability depending on the use case.
Examples:
Eventual Consistency: IoT Data Ingestion: High-volume sensor data can tolerate slight delays in propagating updates to all replicas. Content Delivery: Product catalogs or social media feeds where slight delays are acceptable.
Strong Consistency: Healthcare Systems ensures accurate patient records during concurrent updates. Order Processing Guarantees that inventory is updated immediately to prevent overselling.
3. Transactions in Distributed Systems
Distributed systems often need to handle transactions — groups of operations that must succeed or fail together but ensuring atomicity, consistency, isolation, and durability (ACID) across distributed nodes is challenging.
Common Approaches:
Relational Databases: Offer ACID guarantees for transactional systems like banking or inventory management.
NoSQL Databases with Transactions: Allow multi-item, ACID-compliant transactions for use cases like transferring funds.
Example: Imagine a payment app. When transferring funds, you need to:
Deduct the amount from one account.
Add it to another account.
Distributed transactions ensure atomicity — both updates succeed or fail together.
Challenges:
Throughput Constraints: Transactions can introduce bottlenecks under high loads.
Scalability: Limited to a specific number of items or data size in some systems.
Simplifying Distributed Transactions: Traditional distributed systems used techniques like 2-Phase Commit (2PC) to ensure node consistency. Modern solutions abstract this complexity with managed transaction support, making it easier for engineers to build reliable systems.
Pro Tip: Use idempotent retries to handle network failures during transactions without introducing duplicates or inconsistencies.
Concrete Example: Consider a distributed order processing system. If a network failure occurs after an inventory reduction, retry logic ensures the inventory reduction is not repeated.
4. Scaling
Scaling distributed systems is about increasing capacity by adding machines (horizontal scaling) while maintaining performance.
Techniques for Scaling:
Dynamic Scaling: Automatically add or remove resources based on demand.
Read Replicas: Scale database reads by adding replicas.
Serverless Scaling: Tools like serverless functions (e.g., AWS Lambda) reduce operational overhead by automatically handling resource scaling for event-driven systems. This is particularly useful for workflows like image processing or real-time notifications.
For a global chat application:
Replicate user messages across regions to ensure low-latency access.
Use caching for frequently accessed messages.
Scale message processing workflows dynamically during peak loads.
Multi-Region Benefits:
Latency Reduction: Replicate data closer to users in different regions.
Disaster Recovery: Provide redundancy so traffic can failover during outages.
Key Takeaways
To build reliable, scalable distributed systems:
Use RPC for inter-service communication and handle retries.
Design for fault tolerance with strategies like data replication and failover.
Balance consistency and availability based on your use case.
Handle distributed transactions with relational or NoSQL databases.
Scale your system horizontally with dynamic scaling, replicas, caching, and serverless workflows.
Distributed systems are complex, but the principles remain universal. Focus on designing systems that embrace failures, balance consistency vs availability, and scale effortlessly to meet user demands.
Enjoyed this article? Follow me for more insights on becoming an Effective Engineer.